As a developer, how often have you had marketing or SEO folks come up to you and say “The website is not SEO optimized. Can you please fix it?”.
While we all know the role of SEO in ranking a website on a search engine, a developer in particular should know that he/she plays an equally important role in helping the SEO team perform better.
Gone are those days when an SEO team used to fill a page with keywords and rank higher. Now, it takes effort from both the development team and also the SEO team to come together and create a compelling user experience on a website.
In this blog, let’s look at some of the technical aspects of SEO and why a developer should know about them.

Let’s Understand Crawling & Indexing
It is important to have an idea about how web crawlers crawl the content on the internet and then index the same, in order to display in the search result. Crawling refers to the process where the bot/crawlers visit new and updated pages on the internet, to be added to their index. Once a page is crawled, the data is collected and stored in order to facilitate accurate & quick information retrieval.
This diagram below gives a quick overview of how Google finds a new URL and what are the next phases and how each phase leads to finally indexing the page on Google and displayed in the search result.
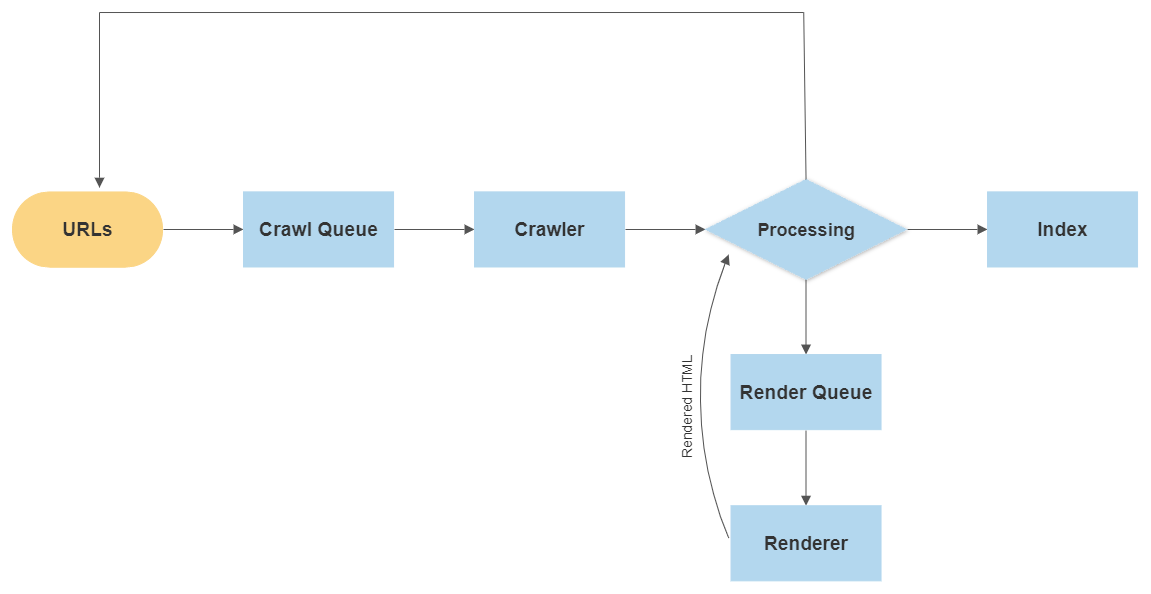
URL Sources: This is where a crawler starts. The new URLs or the updated ones are found through Sitemaps or also from various links on other pages.
Crawl Queue: Once the URLs are listed, they are prioritized & then added to the crawl queue. This list has all the URLs which are to be crawled by Google.
Crawler: This system basically grabs or reads the content of the pages.
Processing: These systems take care of the canonicalization, and ensure that the pages that are crawled are sent to the renderer, and the pages that are rendered are moved forward for indexing.
Renderer: This is where a page is loaded like how a browser would. Google needs to understand or see how a page looks like, from a user’s perspective. At this point, Google can see what most users can.
Index: As the pages are crawled and rendered, they are stored to be displayed to the user.
Robots.txt: Rules for site access
A Robots.txt is a straightforward plain text file, with certain rules. The purpose of this file is to tell/instruct search engines bots/crawlers which URL can they access on this site. The crawl instructions are in a specific way to “disallow” or “allow” the behavior of the user agent (crawlers)
For example:
This instruction specifies that the msnbot should not crawl any URL on the website:
User-agent: msnbot
Disallow: /
This guide from Google is an excellent reference for various types of instructions on Robots.txt
Mobile First Indexing
Google has always been working on returning accurate and relevant search results for all the queries on the search engine. On top of everything that Google has worked on, sits “mobile-friendliness”. Starting from 2015 when mobile friendliness became a factor for ranking in search results, and then in 2018, when mobile speed became a ranking factor, Google has always given this a priority.
And as of 2021, Google plans to switch all of its sites on the web to mobile-first indexing. This indicates that Google will predominantly start using the mobile version of a website’s content for indexing and also ranking on the search results. Developers know what this means for them!!
While Google recommends taking number of steps to ensure that a website is optimized for mobile devices, the top three which are to be considered are:
- Responsive design
- Mobile page load time
- Structured Data
Google offers amazing tools to check if a website is mobile friendly. On top of that, Google Search Console also is an amazing platform to check on various mobile related errors for the site and staying on top of it.
Structured Data
Information + Organized = Organized Information = Structured Data
Structured Data, in a general sense, is an organized way of presenting information about a web page. Let us compare the two search results on Google.
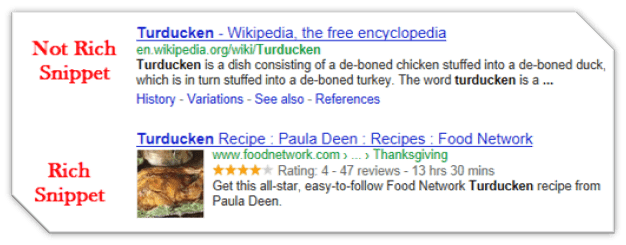
The first one is a simple link with some meta description. The second/bottom result has much more information and is what we call as a Rich Snippet. This information compels a reader to click on this link to find more.
One thing which we should know is that Structured Data does not directly contribute to a website’s ranking on Google. Structured Data is NOT one of the ranking factors. However, it offers various benefits that can help a site in ranking better.
Google provides an amazing list of various types of schema markups which can be used, depending on what type of information you have on your page.

Other Factors
While I’ve covered only a couple of major technical SEO factors which help a developer in building an optimized website, there are few more which are absolutely necessary. Some of them include:
Meta Tags: Meta tags help a search engine in identifying the key aspects (meta data) of a page and plays a major role in search result ranking.
URL Structures: URL structures is one of the most underrated factors when we talk about SEO. URLs need to be simple, easy to understand and less cluttered.
Sitemaps: Like we discussed earlier in this article, sitemaps help search engine crawlers to identify all the pages on a website.
Image Alt Tags: Another underrated factor in SEO, image alt tags provide context to what an image is displaying, helping the crawlers understand the content on the page better.
Traffic tracking: There is absolutely no use in optimizing the website if you are not tracking your progress and improving upon it. For that, tracking the traffic on the website and understanding the behavior of the users on a website becomes important. Tools like Google Analytics & Google Search Console provide a pretty good insight on the website traffic.

Shri Ganesh Hegde
Related Insights

Don't Miss Out!



